Um Ambiente Simples Usando Kubernetes e OpenShift Next Gen — Parte 3
Mar 9, 2017 00:00 · 584 words · 3 minute read
by Lucas Abreu
Este post é a terceira parte de uma série sobre o básico necessário para usar o Kubernetes, caso você não tenha lido o post anterior recomendo lê-lo e depois voltar aqui para não ficar perdido.
Parte 1 — Conceitos Básicos: clique aqui
Parte 2 — Construindo o Ambiente: clique aqui
Parte 4 — Segredos: clique aqui
Como comentei no post anterior existem alguns problemas no ambiente que construí, e o princípial deles é que os Pods não totalmente efêmeros, ou seja, se eu adicionar novos dados nele, no momento que o Pod fosse destruído os dados iriam junto e sem backup !
E agora iremos tratar esse primeiro problema. Caso não tenha mais os fontes até o estado do post anterior, ou prefira acompanhar o meu andamento, pode pode pegá-los aqui: https://github.com/lucassabreu/openshift-next-gen/tree/v1; ou executar:
git clone -b v1 \
https://github.com/lucassabreu/openshift-next-gen.git
Volumes Persistentes
Podemos testar esse problema conectando no Pod e adicionando alguns dados e então destruindo ele para ver o efeito. Vou adicionar um registro sobre para Homens no Sábado, pois é um dia sem nenhuma informação e facilita a visualização.
 Antes… sem dados
Antes… sem dados
Para acessar o Pod usa-se o comando oc rsh
Entrando novamente na aplicação e indo em “Sunday”, tenho um gráfico com dados para os Homens.
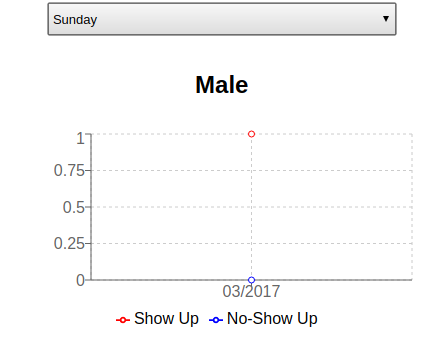 isso se o seu contêiner não morrer no caminho
isso se o seu contêiner não morrer no caminho
Para concluir o teste, basta apagar o Pod com oc delete pods -l name=db-pod ou oc delete pod db-deployment-xyz, esperar o Pod ser recriado e então ver que as alterações nos dados se foram:
:’(
Para resolver esse problema o Kubernetes possui os **Persistent Volume Claims (PVC) **que permitem definir volumes que existem fora do ciclo de vida de um Pod, ou seja, mesmo que todos os Pods sejam destruídos, o PVC irá manter os dados em si.
Podemos utilizar vários tipos de volumes em um PVC para armazenar os dados, no caso do OpenShift o padrão é EBS, que são volumes armazenados dentro do AWS da Amazon, mas existe a opção de usar volumes do Google Cloud, do Azure, Locais, etc; no Kubernetes.
Mas no momento o OpenShift esta ofertando apenas o EBS. Abaixo esta a definição do PVC:
Depois de um momento o OpenShift irá criar um volume e disponibilizá-lo, agora é preciso vincular ele com os db-pods, para isso basta alterar os volumes no db-deployment:
Duas coisas foram alteradas no db-deployment:
O nome do volume mudou, isso é necessário porque estamos fazendo uma mudança de tipo de volume, e o Deployment não consegue alterar o tipo, mas se temos um novo, então tudo bem.
Adicionei a tag persistentVolumeClaim no volume novo e apontei para o PVC que criei agora a pouco.
Executo o comando oc apply -f db-deployment.yml e o Deployment irá destruir os Pods antigos e criar novos usando o PVC.
Agora se replicarmos os comandos de para incluir registros e destruir o Pod do MySQL, quando o Deployment recriar o Pod ele manterá os dados.
Outro ponto que esta desconfortável no meu ambiente é o fato das senhas e usuários estarem expostas diretamente nas configurações. O Kubernetes oferece uma solução para esse problema, que irei abordar no próximo post.
Próximo Post:
Gostou do post e achou útil? Dê um **like **❤ abaixo para ajudar na divulgação e para que mais pessoas tenham acesso 😄, e volte amanhã para acompanhar essa série sobre Kubernetes !